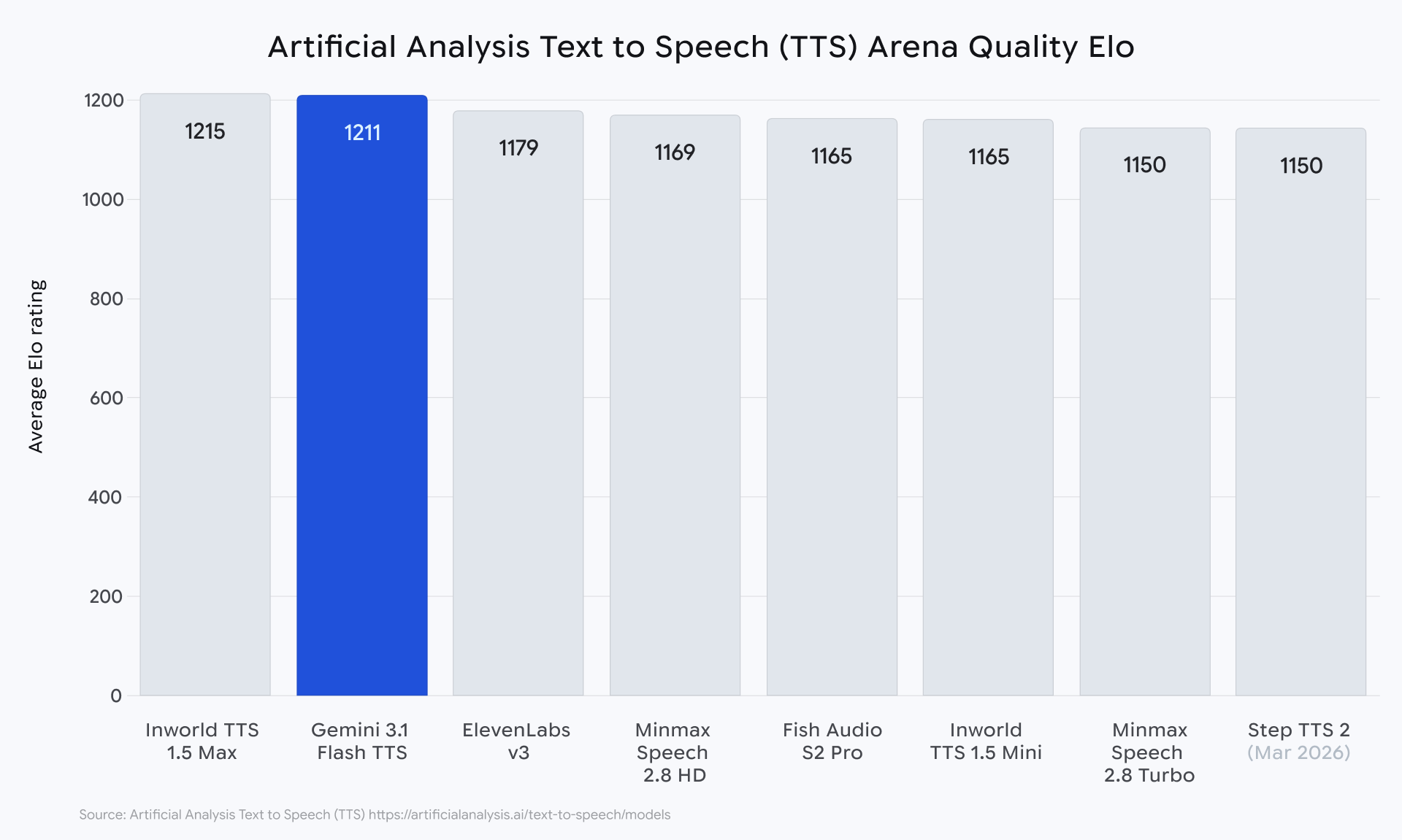
Новая TTS-модель умеет управлять подачей речи прямо внутри текста — через теги вроде «шёпотом» или «кричит» — и, по данным Artificial Analysis, уже обошла ElevenLabs v3 по качеству синтеза.
Google добавила в Gemini 3.1 Flash поддержку более продвинутой генерации речи. Модель умеет превращать текст в естественно звучащее аудио и понимает встроенные аудиотеги в квадратных скобках, которые задают манеру исполнения — например, шёпот, крик или более эмоциональную подачу.
В независимом рейтинге Artificial Analysis модель Gemini 3.1 Flash TTS сейчас стоит выше Eleven v3 от ElevenLabs. Выше неё в таблице находится только Inworld TTS 1.5 Max.
Google пишет, что функцию можно использовать через Gemini API и тестировать в Google AI Studio. Для подключения к продуктам и сервисам доступны те же инструменты экосистемы Gemini и Vertex AI, что и для других моделей линейки.
Отдельный акцент компания делает на мультиязычности: модель поддерживает десятки языков, а встроенные теги позволяют точнее управлять интонацией и стилем озвучки без отдельной настройки голоса. Это делает её заметно ближе к сценариям, где раньше чаще выбирали ElevenLabs.